

先做个广告:如需代注册GPT4帐号或代充值 GPT4.0会员(plus),请添加站长微信:gptchongzhi
没错,这次你无需自己整理笔记,因为 OpenAI 已经为你整理好了。
 推荐使用GPT中文版,国内可直接访问:https://ai.p6p6.cn
推荐使用GPT中文版,国内可直接访问:https://ai.p6p6.cn
据说,这份指南汇聚了我们大家在过去 6 个月中使用 GPT-4 的经验和心得,里面包含了你、我和其他用户的提示和技巧。
虽然总结下来只有六个策略,但细节丝毫不含糊。
除了普通的 GPT-4 用户可以从中获得提示技巧,应用开发者或许也能找到一些创意的灵感。
网友们纷纷留下他们的"读后感":
"真是太有意思了!总结来说,这些技巧的核心思想主要有两点。首先,我们需要提供更具体的细节提示,让模型有更充分的信息。其次,对于复杂的任务,我们可以将其拆分为一系列小任务来完成。"

OpenAI 表示,这份指南目前仅适用于 GPT-4。(当然,你也可以尝试在其他 GPT 模型上使用。)
赶快看一眼,这份指南里面有哪些好东西吧。
/ 策略一:明确指令要求 /
要知道,GPT-4 可不会"读心术",所以你要把你的需求写得明明白白。
当模型输出太啰嗦时,你可以要求它回答简洁明了。相反地,如果输出太简单,你可以要求它用专业水平的语言来写。
如果你对 GPT 输出的格式不满意,那就先展示给它你期望的格式,再要求它以同样的方式输出。
总之,尽量避免让 GPT 模型去猜测你的意图,这样结果更可能符合你的预期。
实用技巧:
1、提供具体细节以获得相关答案
为了让输出和输入更相关,你可以向模型提供更多重要的细节信息。
比如,你想要让 GPT-4 总结一次会议的记录,你可以在描述中增加更多细节:
"将会议记录总结成一段文字。然后,再编写一个 Markdown 列表,列出与会人员及其主要观点。最后,如果与会人员对下一步行动有建议,请一并列出。

2、让模型扮演特定角色
通过改变系统消息的形式,GPT-4 会更容易担任特定角色,这比仅仅在对话中提出要求更加有效。
例如,规定模型回复一个文件,并在每个段落中添加有趣的评论:

3、使用分隔符清晰标示不同部分
使用"""三重引号"""、

4、明确步骤以获取理想结果
某些任务按步骤进行会更好。因此,最好明确指定一系列步骤,这样模型就可以更轻松地遵循这些步骤,并输出理想结果。可以在系统消息中定义回答的步骤。

5、提供示例
如果你想要模型按照一种特定的样式输出,而这种样式无法用准确的方式描述出来,你可以提供示例。提供示例后,只需要告诉模型"按照这个示例的风格写就可以了",它就会根据示例的风格来进行描述。

6、指定所需输出长度
你还可以要求模型生成特定数量的单词、句子、段落、项目符号等。不过,在生成特定数量的单词/字时,结果可能会有一定的误差。

/ 策略二:提供参考文本 /
当涉及到复杂的话题、引用和 URL 等内容时,GPT 模型可能会胡说八道。
为了减少虚构性回答的出现,你可以为 GPT-4 提供参考文本,让它参考后给出更可靠的回答。
实用技巧:
1、让模型参考文本进行回答
如果我们能够向模型提供一些与问题相关的可信信息,就可以指导它使用这些信息来组织回答。
2、让模型引用参考文本进行回答
如果在之前的对话输入中已经提供相关信息,我们还可以直接要求模型在回答中引用这些信息。
需要注意的是,可以通过编程方式对模型在输出中引用的部分进行验证和注释。

/ 策略三:拆分复杂任务 /
相比之下,当处理复杂任务时,GPT-4 可能会出错。
然而,我们可以采用一种巧妙的策略,将复杂任务拆解成一系列简单任务的工作流程。
这样一来,前面任务的输出就可以被用于后续任务的输入。
就像在软件工程中将一个复杂系统分解为一组模块化组件一样,将任务分解成多个模块也可以让模型表现更出色。
实用技巧:
1、进行意图分类
对于需要处理许多独立情况的任务,可以先进行意图分类。
然后,根据分类确定所需的指令。
例如,对于一个客户服务应用程序,可以对查询进行分类(计费、技术支持、账户管理、一般查询等)。
当用户提出以下查询时:
"我需要让我的互联网恢复正常。"
通过分类,可以确定用户的具体需求,并向 GPT-4 提供更具体的指令,以实现下一步操作。
例如,假设用户在寻求"故障排除"方面的帮助,那么可以设定下一步的计划:
"请用户检查所有电缆是否连接正常…"

2、对先前的对话进行概括或筛选
由于 GPT-4 的对话窗口有限制,上下文不能太长,不能无限制地进行对话。
但并非没有解决办法。
一种方法是对先前的对话进行概括。当输入的文本长度达到了预设的阈值时,可以触发一个查询,将部分对话进行概括,并将概括的部分作为系统消息的一部分。
另一种方法是在对话过程中,在后台对前面的对话进行概括。
此外,还可以使用基于嵌入的搜索,在对话过程中进行高效的知识检索。
3、逐段概括长文档,并递归构建完整概述
对于较长的文档,可以进行逐段的概括,然后将每个部分的概括组合成一个整体的概述。
这个过程可以递归进行,直到整个文档被概括。
但某些部分可能需要前面部分的信息才能理解后面的部分。在进行概括时,可以将先前内容的"摘要"和当前部分一起综合考虑。
简单来说,通过将前面部分的"摘要"与当前部分结合,进行概括。
OpenAI 之前在基于 GPT-3 训练的模型上进行了概括书籍的研究,达到了不错的效果。
/ 策略四:给 GPT 足够的"思考"时间 /
当你被问到"17 乘 28 等于多少"的时候,你可能无法立刻给出答案,但你可以通过稍微思考一下来计算出结果。
同样的道理,当 GPT-4 收到问题时,它不会花时间思考,而是试图立刻给出答案,这可能导致推理出错。
因此,在让模型给出答案之前,你可以要求它进行一系列的推理过程,以帮助它通过推理来得出正确的答案。
实用技巧:
1、让模型制定解决方案
有时候,如果我们明确指示模型从基本原理出发进行推理,会获得更好的结果。
比如,假设我们想要让模型评估学生的数学问题解答方案。
最直接的方法是简单地询问模型学生的方案是否正确。

在上图中,GPT-4 认为学生的方案是正确的。
但实际上学生的方案是错误的。
这时候,你可以通过提示模型生成自己的解决方案,以引起其注意。

生成了自己的解决方案之后,再进行一遍推理,模型就能意识到学生的解决方案有误。
2、隐藏推理过程
上面提到了让模型进行推理,给出解决方案。
但在某些应用中,模型得出最终答案的推理过程不适合与用户共享。
比如,在作业辅导中,我们希望鼓励学生自己解题,而不是让模型给出完整的解答。但模型对学生答案的推理可能会向学生展示答案。
这时候我们可以采用"内心独白"策略,让模型将输出中需要对用户隐藏的部分放入结构化格式中。
然后,在呈现输出给用户之前,对输出进行解析,并且只呈现部分输出。
就像下面这个示例:
首先,让模型制定自己的解决方案(因为学生的方案可能是错误的),然后将学生的解决方案与模型的解决方案进行对比。
如果学生解答的某一步错了,就让模型给出一点提示,而不是直接给出正确答案。
如果学生还是不对,就再次提示上一步。

还可以使用"查询"策略,其中隐藏除了最后一步的所有查询。
首先,让模型自己解决问题。由于这个初始查询不需要学生的解答,可以省略它,所以模型的解决方案不会受到学生解决方案的影响。

接下来,让模型使用所有可用的信息来评估学生的解答是否正确。

最后,让模型通过自我分析充当导师的角色。
"你是一位数学导师。如果学生的答案有错误,请进行提示而不需要揭示答案。如果学生的答案正确,只需给予鼓励性评论。"
3、询问模型是否遗漏了任何内容
假设我们希望 GPT-4 列举与特定问题相关的源文件摘录。在列举每个摘录之后,模型不确定是否继续写入下一个摘录,或者是停止。
如果源文件很大,在某些情况下模型可能会提前停止,导致没有列出所有相关摘录。
在这种情况下,通常可以让模型进行后续查询,找出之前处理中遗漏的摘录。
也就是说,当模型生成的文本太长而无法一次性生成时,可以让它进行检查,补充遗漏的内容。

/ 策略五:借力他人工具 /
虽然 GPT-4 非常强大,但并非万能。
我们可以借助其他工具来补充 GPT-4 的不足。
例如,结合文本检索系统,或者利用代码执行引擎。
在让 GPT-4 回答问题时,如果有一些任务可以由其他工具更可靠、更高效地完成,我们可以将这些任务交给它们来完成。这样既能发挥各自的优势,又能让 GPT-4 发挥最佳水平。
实用技巧:
1、使用基于嵌入的搜索实现高效的知识检索
这一技巧在前面已经提到过。
通过向模型提供额外的外部信息,有助于生成更好的回答。
例如,如果用户询问有关特定电影的问题,将电影的相关信息(如演员、导演等)添加到模型的输入中可能非常有帮助。
文本嵌入是一种用于衡量文本字符串相关性的向量。相似或相关的字符串将具有较近的嵌入。加上快速向量搜索算法的支持,可以使用嵌入来实现高效的知识检索。
特别地,文本语料库可以分割成多个部分,每个部分都可以进行嵌入和存储。然后,给定一个查询,可以进行向量搜索以找到与查询最相关的语料库中的嵌入文本部分。
2、使用代码执行引擎实现更准确的计算或调用外部 API
不能单纯依赖模型自身进行准确的计算。
如果需要,可以指示模型编写和运行代码,而非进行自主计算。
可以将要运行的代码放入特定格式中,并在生成输出后提取和运行代码。代码执行引擎(例如 Python 解释器)的输出可以作为下一个输入。

另一个很好的应用场景是调用外部 API。
如果将 API 的正确使用方式传达给模型,它就可以编写代码来使用该 API。
可以通过向模型展示文档和/或代码示例的方式来指导模型使用 API。

在这里,OpenAI 特别强调了一个重要警告⚠️:
执行由模型生成的代码在本质上不安全,任何试图执行此操作的应用程序都应采取预防措施。特别是,需要一个沙盒代码执行环境来限制不受信任的代码可能造成的潜在危害。
/ 策略六:系统地测试修改 /
有时候很难确定一个修改是使系统变得更好还是变得更差。
通过观察一些示例可能会发现哪种改变更好,但在样本数量很少的情况下,很难区分是真的改进了还是只是偶然。
也许这个"修改"在某些输入上能提升效果,但会降低其他输入的效果。而评估程序对于优化系统设计来说非常有用。好的评估有以下几个特点:
1)代表现实世界的用法(或多或少)
2)包含许多测试用例,以获得更大的统计功效(见上表)
3)易于自动化或重复
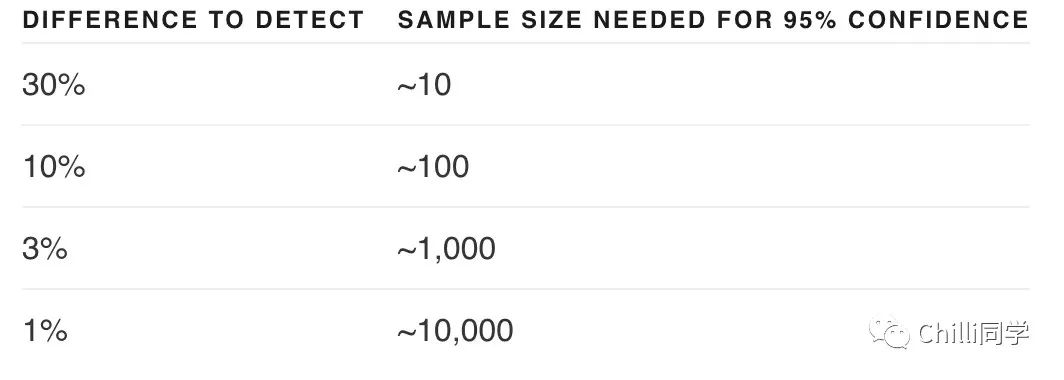
对输出进行评估可以由计算机进行评估,也可以由人工进行评估,或者两者结合进行。计算机可以使用客观标准进行自动评估,也可以使用某些主观或模糊标准,如使用模型来评估模型。
OpenAI 提供了一个开源软件框架——OpenAI Evals,它提供了创建自动评估的工具。
当存在一系列高质量的输出时,基于模型的评估就会非常有用。
实用技巧:
1、参考标准答案评估模型输出
假设已知问题的正确答案应参考一组特定的已知事实。
然后,我们可以询问模型答案中包含多少必需的事实。
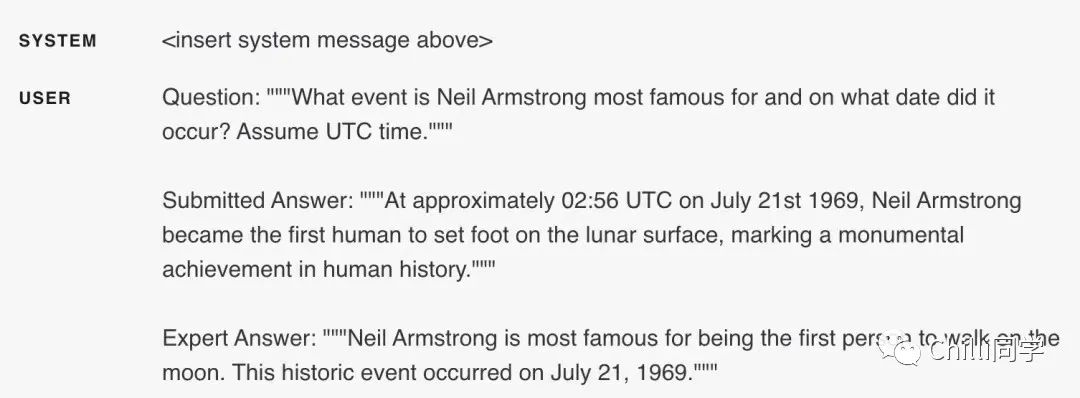
例如,使用下面这个系统消息,
给出必要的已知事实:
"尼尔·阿姆斯特朗是第一个在月球上行走的人。"
"尼尔·阿姆斯特朗第一次登上月球的日期是 1969 年 7 月 21 日。"
如果答案中包含了已提供的事实,模型将回答"是"。反之,它将回答"否"。最后,模型将统计有多少个"是"的答案:

下面是一个示例输入,其中包含了两个必要事实(有事件和日期):

以下示例输入仅满足一个必要事实(没有日期):

而下面的示例输入中没有包含任何必要事实:
这种基于模型的评估方法有很多变化形式,需要追踪候选答案与标准答案之间的重叠程度,并追踪候选答案是否与标准答案存在矛盾之处。

例如,下面的示例输入中,答案与标准答案是不同的,但与专家答案(标准答案)没有矛盾:

而下面这个示例输入中,答案与专家答案完全相反(认为尼尔·阿姆斯特朗是第二个在月球上行走的人):

最后一个示例是带有正确答案的示例输入,该输入还提供了比必要信息更详细的描述(时间到秒并指出这是人类历史上的一个伟大时刻):
参考链接:
[1]https://platform.openai.com/docs/guides/gpt-best-practices
[2]https://www.reddit.com/r/OpenAI/comments/141yheo/openai_recently_added_a_gpt_best_practices_guide/
代充值")
本文链接:https://shikelang.cc/post/818.html
原文链接:https://shikelang.cc/post/818.html
































































评论 ( 0 )